
Our Blog

[ad_1]
Depuis le premier jour du référencement, les spécialistes du marketing tentent de déterminer les facteurs dont Google tient compte pour classer les résultats dans les SERP. Dans ce tout nouveau Whiteboard Friday, Russ Jones discute de la théorie qui sous-tend ces facteurs de classement, et nous donne quelques définitions et vocabulaire améliorés à utiliser pour en discuter.
Cliquez sur l’image du tableau blanc ci-dessus pour ouvrir une version haute résolution dans un nouvel onglet !
 ;
Transcription de la vidéo
Bonjour à tous. Bienvenue à un autre vendredi du tableau blanc. Aujourd’hui, nous allons parler des facteurs de classement et de la théorie qui les sous-tend, et nous espérons dépasser certaines des controverses qui ont surgi au fil des ans, alors que nous venons tout juste de nous parler.
Vous voyez, les facteurs de classement sont présents depuis le premier jour de l’optimisation des moteurs de recherche. Nous avons essayé, en tant que SEO, d’identifier exactement ce qui influence l’algorithme. C’est ce que nous allons examiner aujourd’hui, mais nous allons essayer de trouver de meilleures définitions et un meilleur vocabulaire afin de ne pas nous répéter les uns les autres et de ne pas nous battre constamment sur la corrélation et non sur la causalité, ou sur une autre sorte de nuance qui n’a pas vraiment d’importance.
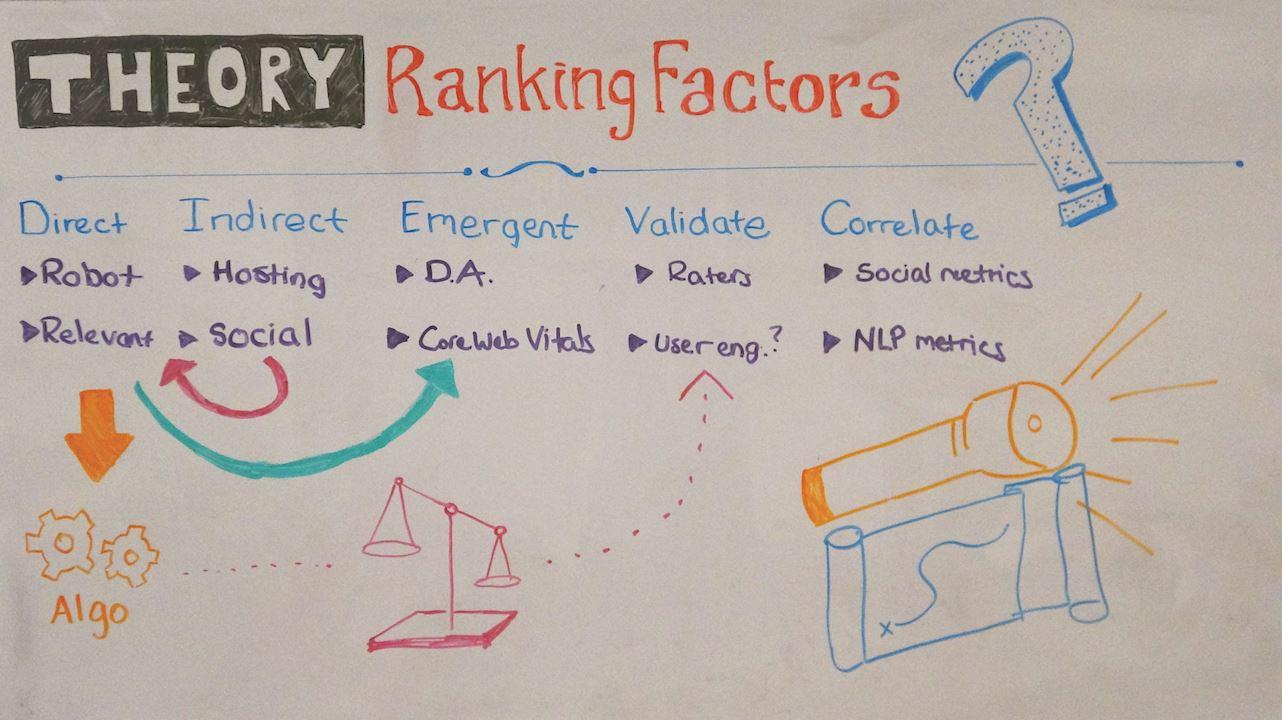
Direct
Commençons donc par le début avec les facteurs de classement direct. C’est la compréhension la plus étroite des facteurs de classement. Cela ne veut pas dire que c’est faux – c’est juste assez restrictif. Un facteur de classement direct serait quelque chose que Google mesure et qui influence directement la performance du résultat de la recherche.
Un exemple classique serait donc votre fichier robots.txt. Si vous apportez une modification à votre fichier robots.txt, et disons que vous interdisez Google, vous aurez un impact direct sur vos performances dans Google. En effet, votre site va disparaître.
Il en va de même, pour l’essentiel, en ce qui concerne la pertinence. Nous ne savons peut-être pas exactement ce que Google utilise pour mesurer la pertinence, mais nous savons que si vous améliorer la pertinence de votre contenuSi vous êtes un citoyen européen, vous avez plus de chances d’être mieux classé. Ce sont donc ce que nous appelons des facteurs de classement direct. Mais il y a évidemment beaucoup plus que cela.
Google a ajouté de plus en plus de fonctionnalités à son moteur de recherche. Ils ont modifié le fonctionnement de leur algorithme. Ils ont ajouté de plus en plus d’apprentissage machine. J’ai donc fait de mon mieux pour essayer de trouver un nouveau vocabulaire que nous pourrions utiliser pour décrire les différents types de facteurs de classement dont nous discutons souvent dans nos différentes communautés ou en ligne.
Indirecte
Maintenant, évidemment, s’il y a des facteurs de classement directs, il semble qu’il devrait y avoir des facteurs de classement indirects. Et ce ne sont que des facteurs de classement ou des interventions que vous pourriez prendre une fois retirés et qui n’influencent pas directement l’algorithme, mais ils influencent certains des facteurs de classement directs qui influencent l’algorithme.
Je pense qu’un exemple classique est l’hébergement. Supposons que votre site commence à devenir plus populaire et qu’il est temps de renoncer à l’hébergement de cPanel à un dollar par mois auquel vous avez souscrit lorsque vous avez commencé votre blog. Vous pourriez choisir de passer, par exemple, à un hébergement dédié qui dispose de beaucoup plus de RAM et de CPU et qui peut gérer plus de threads pour que tout aille plus vite.
Le temps de passage au premier octet est plus rapide. Google ne dispose pas d’un algorithme qui va fouiller votre serveur et identifier exactement le nombre de cœurs de processeur. Mais il existe un certain nombre de facteurs de classement direct, qui sont peut-être liés à l’expérience de l’utilisateur ou à la vitesse des pages, et qui peuvent être influencés par votre environnement d’hébergement.
Par la suite, nous avons de bonnes raisons de croire que l’amélioration de votre environnement d’hébergement pourrait avoir une influence positive sur votre classement de recherche. Mais ce ne serait pas une influence directe. Elle serait indirecte.
Il en serait de même pour les médias sociaux. Même si nous sommes pratiquement sûrs que Google ne se contente pas de dire : « D’accord, celui qui est le plus populaire sur Twitter va se classer », il y a de bonnes raisons de croire qu’investir votre temps, votre argent et votre énergie dans la promotion de votre contenu sur les médias sociaux peut en fait influencer vos résultats de recherche.
Un exemple parfait serait la promotion d’un article sur Facebook, qui est ensuite repris par une publication en ligne et qui renvoie ensuite à votre site. Ainsi, bien que l’activité des médias sociaux en elle-même n’ait pas directement influencé vos résultats de recherche, elle a influencé les liens, et ces liens ont influencé vos résultats de recherche.
On peut donc appeler ces facteurs de classement indirects. Par politesse, lorsque quelqu’un parle des médias sociaux comme d’un facteur de classement, ne supposez pas immédiatement qu’il veut dire qu’il s’agit d’un facteur de classement direct. Ils peuvent très bien signifier qu’il est indirect, et vous pouvez leur demander de préciser : « Eh bien, qu’est-ce que vous voulez dire ? Pensez-vous que Google mesure l’activité des médias sociaux, ou dites-vous qu’un meilleur travail sur les médias sociaux est susceptible d’influencer les résultats de recherche d’une manière ou d’une autre » ?
Cela fait donc partie du processus visant à éliminer les différences entre les facteurs de classement. Cela nous donne la possibilité de communiquer à leur sujet sans, disons, confondre ce que nous entendons par les mots.
Émergent
Maintenant, le troisième type est probablement celui qui va être le plus controversé, et je suis en fait d’accord avec cela. J’aimerais parler dans les commentaires ou sur Twitter de ce que j’entends exactement par « facteurs de classement émergents ». Je pense qu’il est important de clarifier ce point d’une manière ou d’une autre, parce que je pense que cela va être de plus en plus important à mesure que l’apprentissage machine lui-même devient de plus en plus important en tant que partie de l’algorithme de Google.
Il y a de très nombreuses années, des optimiseurs de moteurs de recherche comme moi ont remarqué que les pages web sur des domaines qui avaient une forte autorité en matière de liens semblaient bien se comporter dans les résultats de recherche organique, même lorsque la page elle-même n’était pas particulièrement bonne, n’avait pas de liens externes particulièrement bons – ou pas du tout, et même n’avait pas de liens internes particulièrement bons.
C’est-à-dire qu’il s’agissait d’une page presque orpheline. Les référenceurs ont donc commencé à se demander s’il existait ou non une sorte d’attribut de niveau de domaine que Google utilisait comme facteur de classement. Nous ne pouvons pas le savoir. On peut demander à Google, mais on ne peut qu’espérer qu’il nous le dira.
Chez Moz, nous avons donc décidé d’essayer d’identifier une série de mesures de liens au niveau du domaine qui prédisent réellement la probabilité qu’une page soit performante dans les résultats de recherche. Nous appelons cela un facteur de classement émergent, ou du moins je l’appelle un facteur de classement émergent, car il est évident que Google ne dispose pas d’une fonction spécifique de type autorité de domaine dans son algorithme.
Mais au contraire, ils disposent également de nombreuses données sur les liens pointant vers différentes pages d’un même domaine. Je pense que ce qui se passe est ce que j’appellerais un facteur de classement émergent, c’est-à-dire que l’influence de plusieurs mesures différentes – dont aucune n’a pour but particulier de créer quelque chose – finit par être facile à mesurer et à parler comme d’un facteur de classement émergent, plutôt que comme faisant partie de tous ses éléments constitutifs.
C’était une sorte de bouchée, alors laissez-moi vous donner un exemple. Lorsque vous faites une sauce si vous cuisinez, l’une des parties les plus courantes serait la production d’un roux. Un roux est un mélange, normalement composé d’un poids égal de farine et de graisse, que l’on utilise pour épaissir la sauce.
Maintenant, je pourrais écrire un livre de recettes entier sur les sauces et ne jamais utiliser le mot « roux ». Il suffit de ne pas l’utiliser, et de décrire le processus de production d’un roux cent fois, mais de ne jamais utiliser le mot « roux », parce que « roux » décrit cet état intermédiaire. Mais il devient très, très utile pour un chef de pouvoir dire à un autre chef (ou à un sous-chef, ou à un cuisinier dans son livre de cuisine), « produire un roux avec » et ensuite, quelle que soit la graisse que vous utilisez, que ce soit du beurre ou de l’huile ou quelque chose de ce genre.
L’analogie est donc qu’il n’y a pas vraiment de roux dans la sauce. Ce qu’il y a dans la sauce, c’est la graisse et la farine. Mais en même temps, il est très pratique de l’appeler roux. En fait, nous pouvons utiliser le mot « roux » pour en savoir beaucoup sur un plat particulier sans jamais parler des ingrédients réels de la farine et de la graisse.
Par exemple, on peut être assez sûr que si un roux est demandé dans un plat particulier, ce plat n’est probablement pas du bacon car ce n’est pas une sauce. Je suppose donc que ce que j’essaie de comprendre ici, c’est qu’une grande partie de ce dont nous parlons avec les facteurs de classement est l’utilisation d’un langage qui est pratique et utile à certaines fins.
Comme l’AD est précieux pour aider à prédire les résultats de recherche, mais il n’a pas besoin de faire partie de l’algorithme pour cela. En fait, je pense qu’il y a un exemple vraiment intéressant qui se passe en ce moment – et nous sommes sur le point de voir un changement des catégories – qui sont Vitals du Web de base.
Google pousse la vitesse des pages depuis un certain temps et nous a fourni plusieurs itérations de différents types de mesures pour déterminer la vitesse de chargement d’une page. Cependant, il semble que Google ait décidé de ne pas promouvoir des mesures individuelles et particulières qu’un site web pourrait prendre pour accélérer la vitesse, mais qu’il souhaite plutôt que vous maximisiez ou minimisiez une valeur émergente particulière qui résulte de la fusion de toutes ces mesures.
Nous savons que les trois différents types de « Core Web Vitals » sont : le premier délai d’entrée, la plus grande peinture de contenu, et le changement cumulatif de la mise en page. Parlons donc du troisième. Si vous avez déjà été sur votre téléphone portable et que vous avez remarqué que le texte se charge avant certains autres aspects et que vous commencez à le lire et que vous essayez de le faire défiler vers le bas et que dès que vous mettez votre doigt là, une annonce apparaît parce que l’annonce a pris plus de temps à se charger et qu’elle bouscule la page, eh bien, c’est le changement de mise en page, et Google a appris que les utilisateurs n’aiment tout simplement pas ça. Donc, même s’ils ne connaissent pas tous les facteurs individuels sous-jacents qui sont responsables de la modification cumulative de la mise en page, ils savent qu’il y a cette mesure, qui explique tout, qui est une excellente sténographie et un moyen vraiment efficace de déterminer si un utilisateur va ou non apprécier son expérience sur cette page.
Ce serait un facteur de classement émergent. Ce qui est intéressant, c’est que Google a maintenant décidé que ce facteur de classement émergent va devenir un facteur de classement direct en 2021. Ils vont déplacer ces facteurs descriptifs qui sont des amalgames de beaucoup de petites choses et les faire influencer directement les résultats de recherche.
Nous pouvons donc voir comment ces différents types de facteurs de classement peuvent aller et venir des catégories. Retour à la question de autorité de domaine. Maintenant, Google a clairement indiqué qu’il n’utilise pas l’autorité de domaine de Moz – bien sûr que non – et qu’il ne dispose pas d’une métrique de type autorité de domaine. Cependant, rien ne dit qu’à un moment donné, ils n’ont pas pu construire exactement cela, une sorte de métrique au niveau du domaine, basée sur des liens, qui est utilisée pour informer sur la façon de classer certaines pages.
Un facteur de classement émergent n’est donc pas coincé dans cette catégorie. Il peut changer. Bon, ça suffit avec les facteurs de classement émergents. J’espère que nous pourrons en parler davantage dans les commentaires.
Validation
Le type suivant que je voulais passer en revue est ce que j’appellerais un facteur de classement validant. Il s’agit d’un autre facteur qui a été assez controversé, à savoir la liste des éléments importants des directives de notation de la qualité, et probablement celui dont on parle le plus est l’E-A-T : Expertise, autorité et fiabilité.
Eh bien, Google a clairement indiqué que non seulement il ne mesure pas l’E-A-T (ou du moins, si j’ai bien compris, il n’a pas de paramètres qui ciblent spécifiquement l’E-A-T), non seulement il ne le fait pas, mais en outre, lorsqu’il collecte les données des évaluateurs de qualité pour savoir si les SERP qu’il examine répondent ou non à ces critères, il n’entraîne pas son algorithme en fonction des données étiquetées qui lui sont fournies par ses évaluateurs de qualité, ce qui, à mon avis, est surprenant.
Il me semble que si vous aviez beaucoup de données étiquetées sur la qualité, l’expertise et l’autorité, vous pourriez vouloir les former contre cela, mais peut-être que Google a découvert qu’elles n’étaient pas très productives. Néanmoins, il est possible que Google ait découvert qu’il n’était pas très productif, nous savons que Google se soucie de l’E-A-Tet nous disposons également de preuves anecdotiques.
C’est-à-dire que les webmasters ont remarqué au fil du temps, en particulier dans les types d’industries « votre argent ou votre vie », que l’expertise et l’autorité semblent compter d’une manière ou d’une autre. J’aime donc appeler ces facteurs de validation du classement parce que Google les utilise pour valider la qualité des SERP et des sites qui sont classés, mais ne les utilise pas en fait d’une manière directe ou indirecte pour influencer les résultats de recherche.
J’en ai un intéressant ici, que j’appellerais l’engagement des utilisateurs, et la raison pour laquelle je l’ai mis ici est que cela reste un facteur de classement assez controversé. Nous ne savons pas exactement comment Google l’utilise, même si nous recevons de temps en temps quelques indices comme Core Web Vitals.
Si ces données sont collectées à partir du comportement réel des utilisateurs dans Chrome, nous avons alors une idée précise de la manière dont l’engagement des utilisateurs pourrait avoir un impact indirect sur l’algorithme, car l’engagement des utilisateurs mesure les « Core Web Vitals », qui, à l’horizon 2021, vont directement influencer les résultats des recherches.
Corrélation
Cette quatrième catégorie de facteurs de classement est donc validante, et la dernière – celle qui me semble la plus controversée – est celle des corrélats. Nous nous retrouvons à chaque fois dans cet argument : « corrélation n’est pas synonyme de causalité », et il me semble que c’est l’affirmation selon laquelle la personne qui ne connaît qu’une chose en matière de statistiques la connaît, et c’est pourquoi elle le dit toujours chaque fois qu’il est question de corrélation.
Oui, la corrélation n’implique pas la causalité, mais cela ne veut pas dire qu’elle n’est pas très, très utile. Parlons donc des mesures sociales. C’est l’une des plus classiques. Plusieurs fois, nous avons mené diverses études sur les facteurs de classement et nous avons découvert une relation directe – une relation forte – entre des choses comme les goûts de Facebook ou les plus de Google dans les classements.
Très bien. Maintenant, presque tout le monde a immédiatement compris que la raison pour laquelle un site aurait plus de « plus » dans Google+ et aurait plus de « plus » dans Facebook, c’est parce qu’il est classé. C’est-à-dire que ce n’est pas Google qui sort et qui dépend de l’API de Facebook pour déterminer comment ils vont classer les sites dans leur moteur de recherche.
Au contraire, une bonne performance dans leur moteur de recherche entraîne du trafic, et ce trafic a alors tendance à aimer la page. Je comprends donc la frustration des clients qui commencent à demander « Eh bien, ces deux choses sont liées ». Pourquoi ne m’obtenez-vous pas plus d’avantages ?
Je comprends cela, mais cela ne veut pas dire qu’il n’est pas utile à d’autres égards. Je vais donc vous donner un bon exemple. Si vous êtes bien classé pour un mot-clé mais que vos mesures de médias sociaux sont moins bonnes que celles de vos concurrents, eh bien, cela signifie qu’il se passe quelque chose dans cette situation qui fait que vos utilisateurs s’engagent mieux avec les sites de vos concurrents qu’avec les vôtres, et c’est important de le savoir.
Cela ne changera peut-être pas votre classement, mais cela pourrait modifier votre taux de conversion. Elle peut augmenter la probabilité que vous soyez trouvé sur les médias sociaux. Plus encore, elle pourrait même influencer vos résultats de recherche. En effet, lorsque vous reconnaissez que la raison pour laquelle votre page ne vous plaît pas est que vous avez un code erroné, que le bouton Facebook ne fonctionne pas, que vous l’ajoutez et que vous commencez à être partagé et que de plus en plus de personnes s’intéressent à votre contenu et y font des liens, eh bien, nous commençons à avoir cet effet indirect sur votre classement.
Donc, oui, la corrélation n’est pas la même chose que la causalité, mais elle a une grande valeur. Il y a un nouveau domaine qui, je pense, va être très, très important pour cela. Il s’agit des mesures de traitement du langage naturel. Il s’agit de diverses technologies différentes qui sont à la pointe du progrès. Eh bien, certaines sont plus anciennes. D’autres sont plus récentes. Mais elles nous permettent de prédire la qualité du contenu.
Maintenant, il y a des chances que nous ne devinions pas la manière exacte dont Google mesure la qualité du contenu. Je veux dire, à moins qu’un document ayant fait l’objet d’une fuite ou quelque chose du genre n’apparaisse, nous n’aurons probablement pas cette chance. Mais cela ne veut pas dire que nous ne pouvons pas être vraiment productifs si nous avons un certain nombre de corrélats, et ces corrélats peuvent alors être utilisés pour nous guider.
J’ai donc dessiné une petite carte ici pour servir d’exemple. Imaginez que c’est le soir et que vous êtes en train de camper, et que vous décidez de faire une petite randonnée, et que vous emportez avec vous, disons, un drapeau ou une série de drapeaux, et que vous marquez le chemin au fur et à mesure pour que, quand il sera plus tard, vous puissiez, à l’aide de votre lampe de poche, suivre les drapeaux, en les ramassant, pour vous ramener au camp.
Mais il fait super sombre, et vous vous rendez compte que vous avez laissé votre lampe de poche au camp. Qu’allez-vous faire ? Eh bien, nous devons trouver un moyen de nous guider pour retourner au camp. Maintenant, évidemment, les drapeaux auraient été la meilleure situation, mais il y a beaucoup de choses qui ne sont pas le camp lui-même et qui ne sont pas le chemin lui-même, mais qui seraient quand même très utiles pour nous ramener au camp. Par exemple, disons que vous venez d’éteindre le feu après avoir quitté le camp. L’odeur de la fumée est un bon moyen pour vous de retrouver le chemin du camp, mais la fumée n’est pas le camp. Ce n’est pas la cause du camp. Elle n’a pas construit le camp. Ce n’est pas le chemin. Elle n’a pas créé le chemin. En fait, la traînée de fumée elle-même est probablement assez éloignée du chemin, mais une fois que vous avez trouvé l’endroit où elle vous croise, vous pouvez suivre cette odeur. Dans ce cas, c’est vraiment précieux, même s’il n’y a qu’une légère corrélation avec l’endroit exact où vous devez vous rendre.
Eh bien, la même chose est vraie quand on parle de quelque chose comme les mesures de la PNL ou les mesures des médias sociaux. Même s’ils n’ont pas d’importance en termes d’influence directe sur les résultats de recherche, ils peuvent vous guider. Ils peuvent vous aider à prendre de meilleures décisions. Vous ne devez pas manipuler ces types de mesures pour leur propre intérêt, car nous savons que les corrélats sont les plus éloignés des facteurs de classement direct – du moins lorsque nous savons que le corrélat lui-même n’est pas un facteur de classement direct.
Très bien. Je sais que c’est beaucoup à digérer, beaucoup à encaisser. J’espère donc que nous avons des éléments à aborder dans les commentaires ci-dessous, et j’ai hâte de discuter avec vous. Je vous souhaite bonne chance. Au revoir.
[ad_2]